



let me explain indexing in SQL Server in simple terms
Imagine you have a big school library with thousands of books, and you need to find a specific book quickly. Without an index, you would have to look at every single book one by one, which would take a very long time.
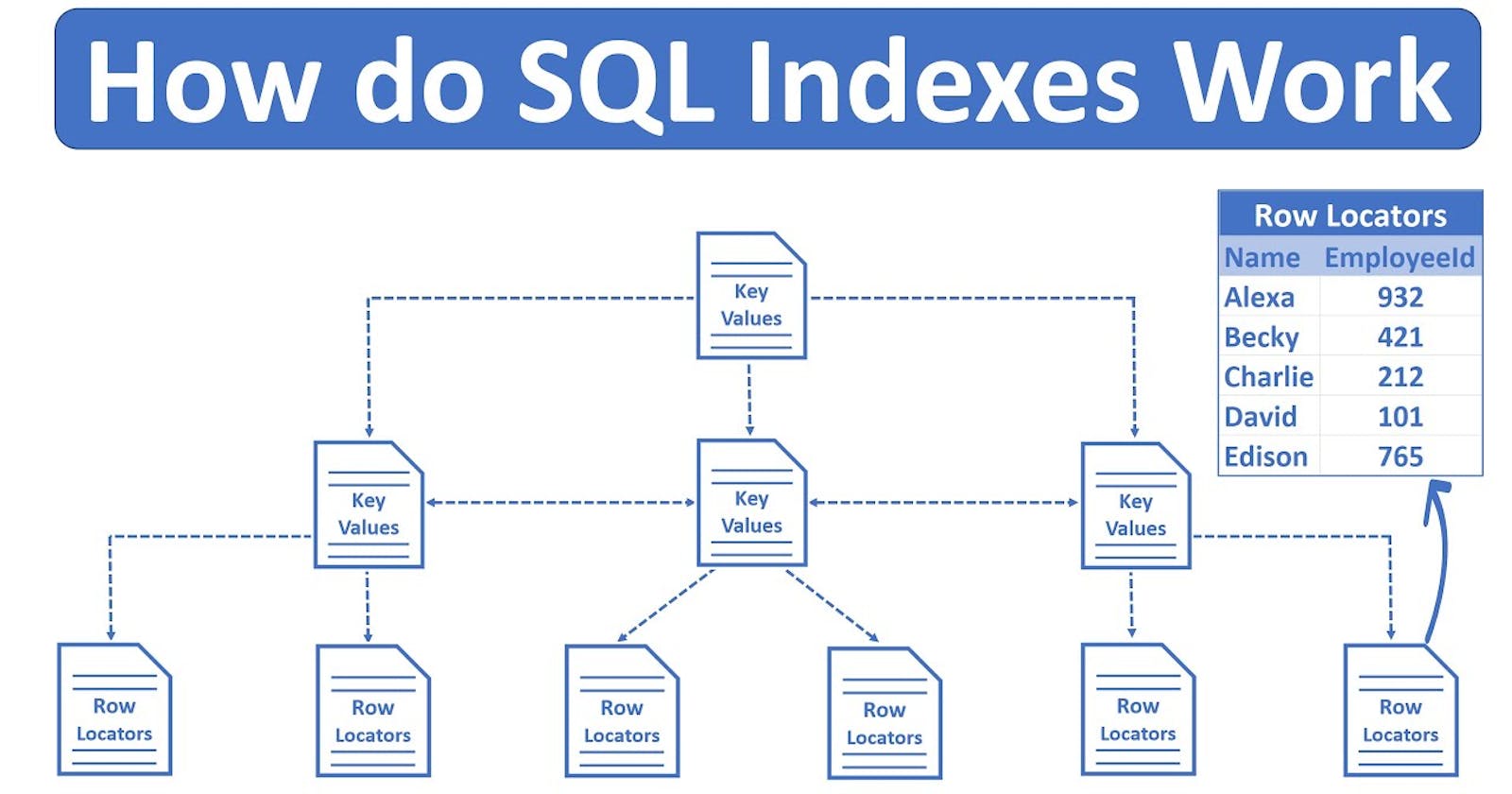
An index in SQL Server is like a special list or a table that helps the computer find the information you're looking for really fast, without having to search through every single piece of data.
For example, let's say you have a table in SQL Server that stores information about all the students in your school, like their names, grades, and addresses. If you want to find all the students who live on a particular street, like "Main Street," without an index, the computer would have to look at every single student's record one by one to find the ones with "Main Street" as their address. That would be really slow, especially if there are thousands or even millions of students in the table.
Instead, you can create an index on the "address" column in the table. This index is like a separate list or table that contains all the addresses in the table, along with the locations or row numbers where those addresses are stored in the main table.
So, when you ask SQL Server to find all the students who live on "Main Street," it can quickly look in the index to find all the row numbers or locations that have "Main Street" as the address, without having to search through the entire table.
Indexes in SQL Server can be used for all sorts of things:
Finding specific records quickly: You can create indexes on columns that you frequently use to search for data, like names, addresses, or order numbers.
Sorting data: Indexes can also help SQL Server sort data quickly, which is useful for things like generating reports or displaying data in a particular order.
Joining tables: When you need to combine data from multiple tables, SQL Server uses indexes to speed up the process of finding matching rows between the tables.
Enforcing data integrity: Indexes can help ensure that each row in a table has a unique value for a particular column, which is important for things like primary keys and avoiding duplicate data.
However, it's important to remember that while indexes can make it much faster to find and work with data, they also take up extra space and need to be maintained. Too many indexes can actually slow things down, so you need to carefully plan which columns and tables should have indexes based on how you'll be using the data.
Types of indexes
Clustered Index
Non-Clustered Index
Unique Index
Composite Index
Clustered Index This is like having all your books arranged in alphabetical order by their titles on a big bookshelf. Each book has its own spot on the shelf, and you can quickly find any book by looking at the titles in order. In SQL Server, a clustered index determines the physical order of how the data rows are stored on disk. Each table can only have one clustered index, and it's often created on a column like an ID or primary key that uniquely identifies each row.
Non-Clustered Index Now imagine you have a separate list or index card for each book, with the book's title and the location where it's stored on the big bookshelf. These index cards are not part of the bookshelf itself, but they make it easier to find the book you want without having to look through the entire shelf. A non-clustered index in SQL Server is like those index cards. It's a separate object that contains the column values and pointers to the actual data rows in the table. You can have multiple non-clustered indexes on a single table, which is useful for different types of queries.
Unique Index This is like having a rule that says you can only have one copy of each book in your collection. If you try to add another book with the same title, it won't let you. A unique index in SQL Server ensures that each value in the indexed column (or combination of columns) is unique across the entire table. This helps maintain data integrity and prevents duplicate values.
Composite Index Imagine you have index cards for your books, but instead of just having the title on each card, you also include the author's name and the publication year. This makes it easier to find a specific book if you know multiple pieces of information about it. A composite index in SQL Server is an index that includes two or more columns from the same table. This can be really useful for queries that filter or sort data based on multiple columns.
SQL Server uses these different types of indexes to help you find and work with data more quickly and efficiently, just like having a well-organized book collection with different ways of finding the books you need.
For example
If you have a database that stores information about products in a store, you might have:
A clustered index on the "ProductID" column, so all the products are physically stored in order of their ID numbers.
A non-clustered index on the "ProductName" column, to quickly find products by their names.
A unique index on the "ProductCode" column, to ensure that each product has a unique code and prevent duplicates.
A composite index on the "CategoryID" and "Price" columns, to help with queries that filter products by category and price range.
By using the right types of indexes, SQL Server can quickly locate the data you need, sort it, and combine it from different tables, without having to scan through every single row of data one by one.
Example for Clustered Index
CREATE Database BookStore;
GO
USE BookStore;
CREATE TABLE Books
(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(50) NOT NULL,
category VARCHAR(50) NOT NULL,
price INT NOT NULL
)
CREATE CLUSTERED INDEX <index_name>
ON <table_name>(<column_name> ASC/DESC)
use BookStore
CREATE CLUSTERED INDEX IX_tblBook_Price
ON Books(price ASC)
Example for NON-Clustered Index
CREATE NONCLUSTERED INDEX <index_name>
ON <table_name>(<column_name> ASC/DESC)
use BookStore
CREATE NONCLUSTERED INDEX IX_tblBook_Name
ON Books(name ASC)